
setup-openshift-heketi-storage无空间
glusterfs 4.1.7 heketi v9.0.0 部署
问题描述
运行setup-openshift-heketi-storage子命令时heketi-cli报告“无空间”错误:
1 | heketi-cli setup-openshift-heketi-storage |
问题原因
运行topology load命令的时候,服务端和heketi-cli的版本不匹配造成的。
解决策略
停止正在运行的heketi pod:
1 | kubectl scale deployment deploy-heketi --replicas=0 |
手动删除存储块设备中的任何签名:
加载拓扑的操作是在gluster 中添加了Peer,所以需要手动detach peer
然后继续运行heketi pod:
1 | kubectl scale deployment deploy-heketi --replicas=1 |
用匹配版本的heketi-cli重新加载拓扑,然后重试该步骤。
gfs集群添加磁盘失败
glusterfs 4.1.7 heketi v9.0.0 部署
问题描述
给gfs集群添加设备时报错
1 | Adding device /dev/sdb ... Unable to add device: Unable to execute command on glusterfs-xp1nx: Can't initialize physical volume "/dev/vdb"of volume group "vg_dc649bdf755667e58c5d779f9d900057" without -ff |
问题原因
原因是/dev/sdb已经创建过了pv,需要删除了重新创建
解决策略
1 | dd if=/dev/zero of=/dev/sdb bs=1k count=1 |
或
1 | pvcreate -ff --metadatasize=128M --dataalignment=256K /dev/sdb |
创建heketidbstrorage失败
glusterfs 4.1.7 heketi v9.0.0 部署
问题描述
给heketi创建持久卷时报错
1 | heketi-cli setup-openshift-heketi-storage |
问题原因
登录相关pod,发现gluster peer status 显示有问题
解决策略
修改/etc/hosts 将所有node节点添加解析记录
创建heketidb卷引发机器重启
glusterfs 7.1 heketi v9.0.0 部署
问题描述
在运行heketi-cli setup-openshift-heketi-storage时发生机器重启,再次登录后发现gluster没有卷信息,但是lvs看已经生成了,手动删除这些lv也会导致机器重启
问题原因
系统内核 < 3.10-863引发的bug
解决策略
升级系统内核,部署gfs时需保证内核不小于3.10-863
调整heketi的日志级别
glusterfs 7.1 heketi v9.0.0
问题描述
heketi的配置文件是通过secrets挂到容器中的,是通过heketi.json文件生成的,查看发现配置文件中并未指明日志的级别。
解决策略
默认的日志级别是debug,如果需要修改,则:
在heketi.json中 “db”: “/var/lib/heketi/heketi.db”,下添加 "loglevel": "info",
注:日志级别(none, critical, error, warning, info, debug)
注意后面的逗号
重新生成heketi-config-secret,重启heketi pod即可。
节点Peer Rejected
glusterfs 7.1 heketi v9.0.0
问题描述
删除一个节点的/var/lib/glusterd/*,从其他健康的gfs节点查看集群成员状态此节点已经变成了Peer Rejected 。
问题原因
此节点uuid改变
解决策略
需要手动恢复:在健康节点查看之前异常节点的uuid。然后修改异常节点的glusterd.info,再把健康节点的uuid拷贝到异常节点的peers目录下,重启异常节点的gfs pod 。
服务挂载卷消失 Server authenication failed
glusterfs 7.1 heketi v9.0.0 kubernetes 1.11.0
问题描述
机器断电重启后发现原先挂载了glusterfs存储的nginx容器里pv没了,查看glusterfs和heketi容器都正常运行,客户端nginx容器也能正常跑起来,查看容器的日志并没有什么报错。
问题原因
查看event中报错信息:
1 | [2019-07-24 08:58:01.548933] E [MSGID: 114044] [client-handshake.c:1144:client_setvolume_cbk] 0-vol_0b6185b748a309fc93431319db6e8343-client-2: SETVOLUME on remote-host failed: Authentication failed [权限不够] |
截图如下:

解决策略
编辑 /etc/glusterfs/glusterd.vol添加option rpc-auth-allow-insecure on;
重启glusterd服务然后删了nginx pod成功找回了挂载卷(数据还在)
transport endpoint is not connected
glusterfs 7.1 heketi v9.0.0
问题描述
客户端挂载盘报错:transport endpoint is not connected
问题原因
卷处于关闭状态、服务器间通信出现问题、glusterfs存储系统间数据不一致都会导致此现象产生。
解决策略
首先应该检查gfs服务是否正常,如果都是Run的状态则查看对应卷的状态
1 | kubectl get pods -n glusterfs |
检查对应的卷的状态
找到对应的pv
1 | kubectl get pv -n $<namespace> |
找到对应的卷
1 | kubectl describe pv $PV |grep Path: |
查看glusterfs volume的状态
1 | kubectl exec -it -n glusterfs $<glusterfs_volume> -- gluster volume info $glusterfs_volume | grep Status |
在客户端查看挂载对应盘的进程是否正常;
若检查glusterfs状态均为正常,则表明其他原因导致(如节点网络异常等),重启该存储盘异常服务即可解决
pv fail状态
glusterfs 7.1 heketi v9.0.0 kubernetes 1.11.0
问题描述
测试时删除pvc时发现pvc已删除但是pv还在,是Failed的状态。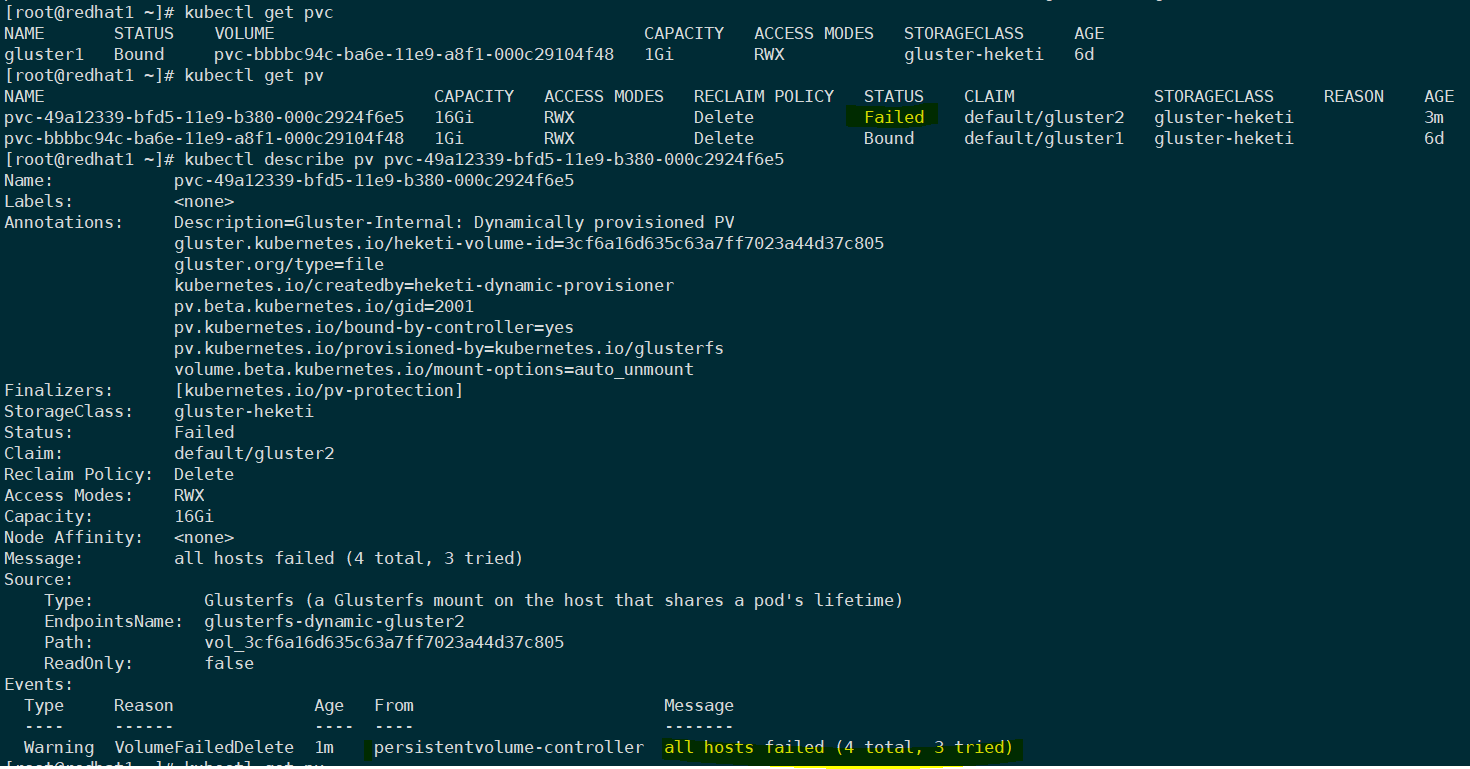
使用heketi-cli volume delete删除卷报错:
1 | heketi-cli volume delete 3cf6a16d635c63a7ff7023a44d37c805 |
先手动将pv删掉
登录其中一台gluster执行如下命令,删除卷时发现报错:
failed: some of the peers are down
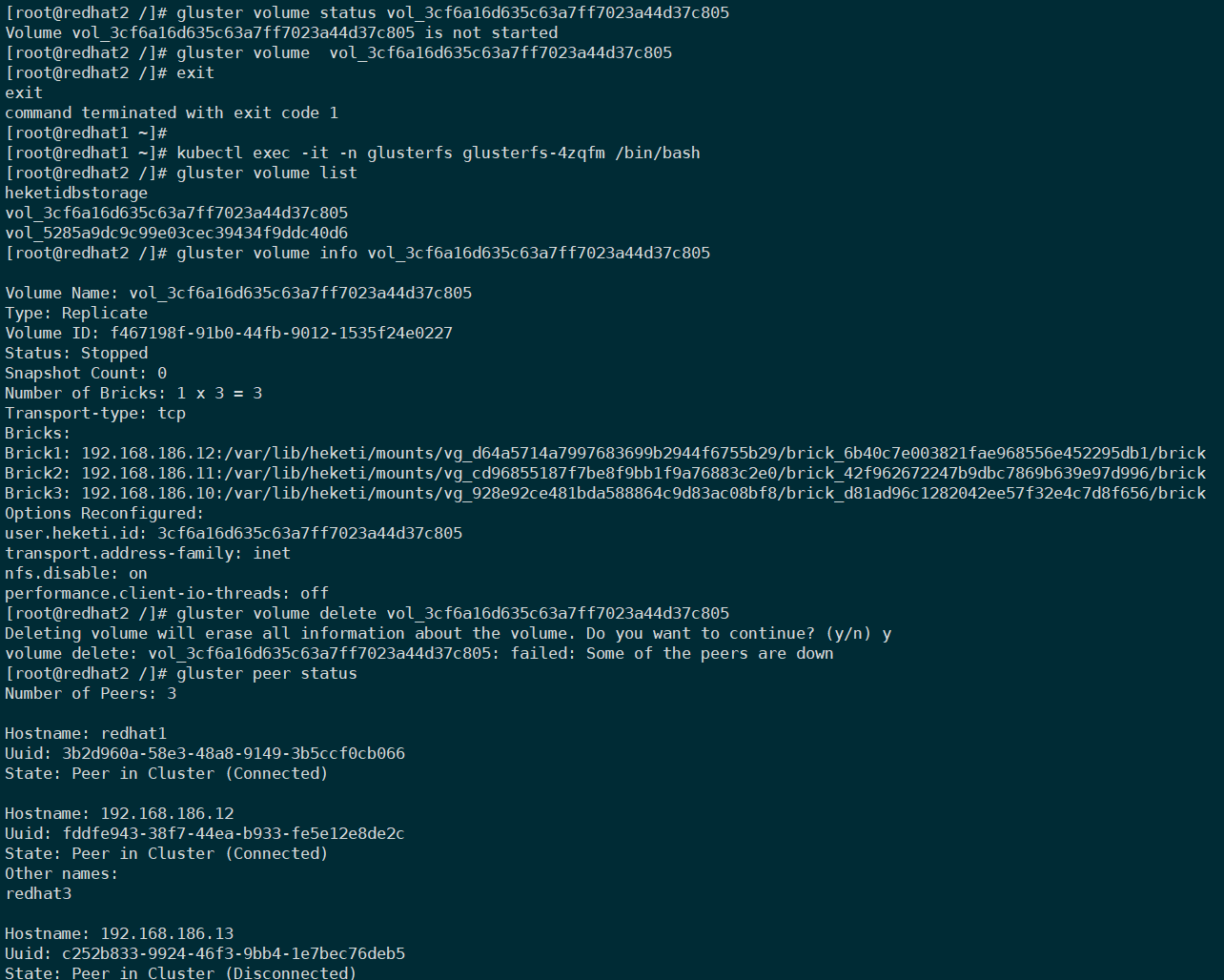
问题原因
因为我测试时把gfs集群中一台机器关机了,手动把这台剔除集群,发现可以删除了。
上面这只是测试,不建议使用,因为heketi中的残留数据还在。
解决策略
最好的方式时恢复那台关机的节点。
如果删除卷必须在信任池中节点都在才可以,那么必须保证信任池的健康。
gfs狂刷日志导致的节点down
glusterfs 4.1.7 heketi v9.0.0 kubernetes 1.11.0
问题描述
其中一个gfs节点启动失败,一直在重启。
问题原因
登录此节点df发现根分区使用率为100%,发现gfs服务频繁刷新产生日志导致。
每次卷的重建,客户端进程glusterfs都会被重启,但进程重启的过程中,新的进程产生,旧的进程并没有被关闭,并且还在持续调用被删除的卷,所以glusterfshd.log日志不停地在输出卷无法连接的错误。在K8s 1.11.0+gfs 4.1.7上可以通过批量创建卷再批量删除卷模拟此场景。
解决策略
临时解决方案先把大的日志备份压缩,重启此pods。如果本地资源紧张也可以直接删除问题日志。
永久解决:
gfs7.1版本已修复此问题。
要保证存储节点有足够的根分区或给/var/挂一块足够的盘(最少30G)
创建pvc pending
glusterfs 7.1 heketi v9.0.0 kubernetes 1.17.0
问题描述
在健康的三节点gfs集群进行测试,进入其中一个gfs pods手动关闭glusterd服务,在k8s中创建pvc,一直pending。查看glusterfs日志:
问题原因
创建卷找不到可用的3副本
解决策略
把glusterd启动即可。
heketi 空间计算与实际brick不匹配
glusterfs 7.1 heketi v9.0.0 kubernetes 1.17.0
问题描述
创建pvc时发现报错没有空间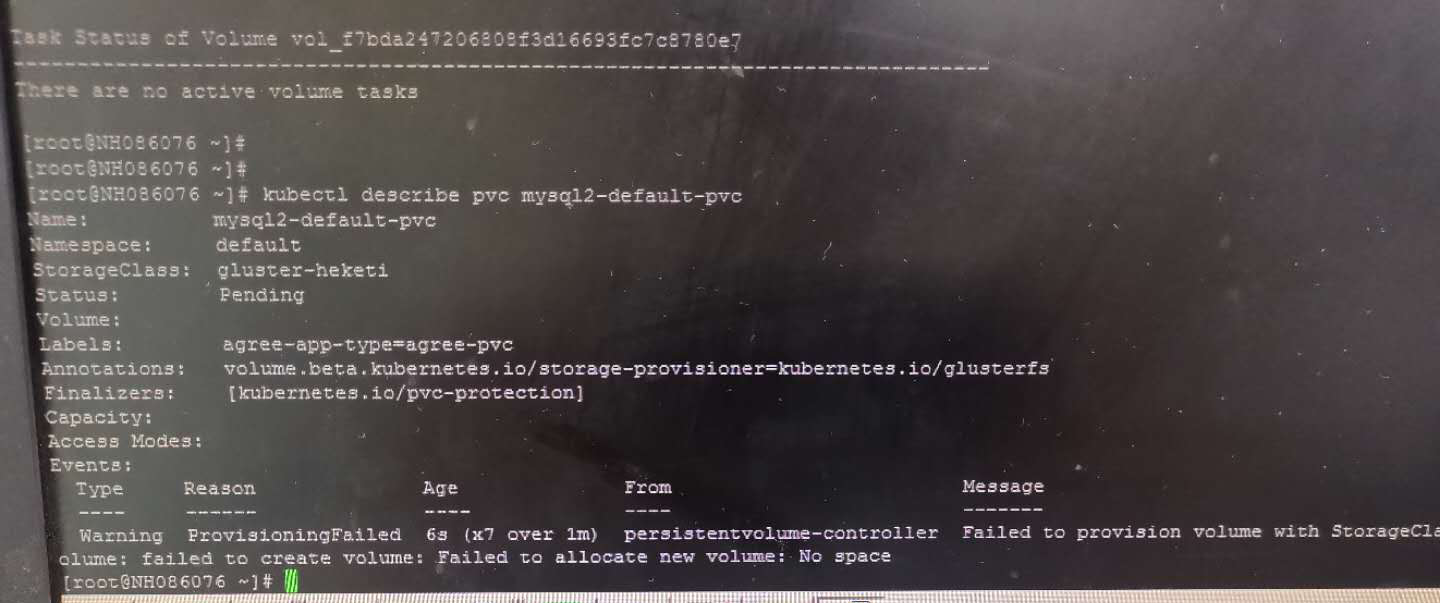
查看heketi中的gfs集群状态发现只创建了3个G的卷但是却显示使用了19个G,没有剩余空间了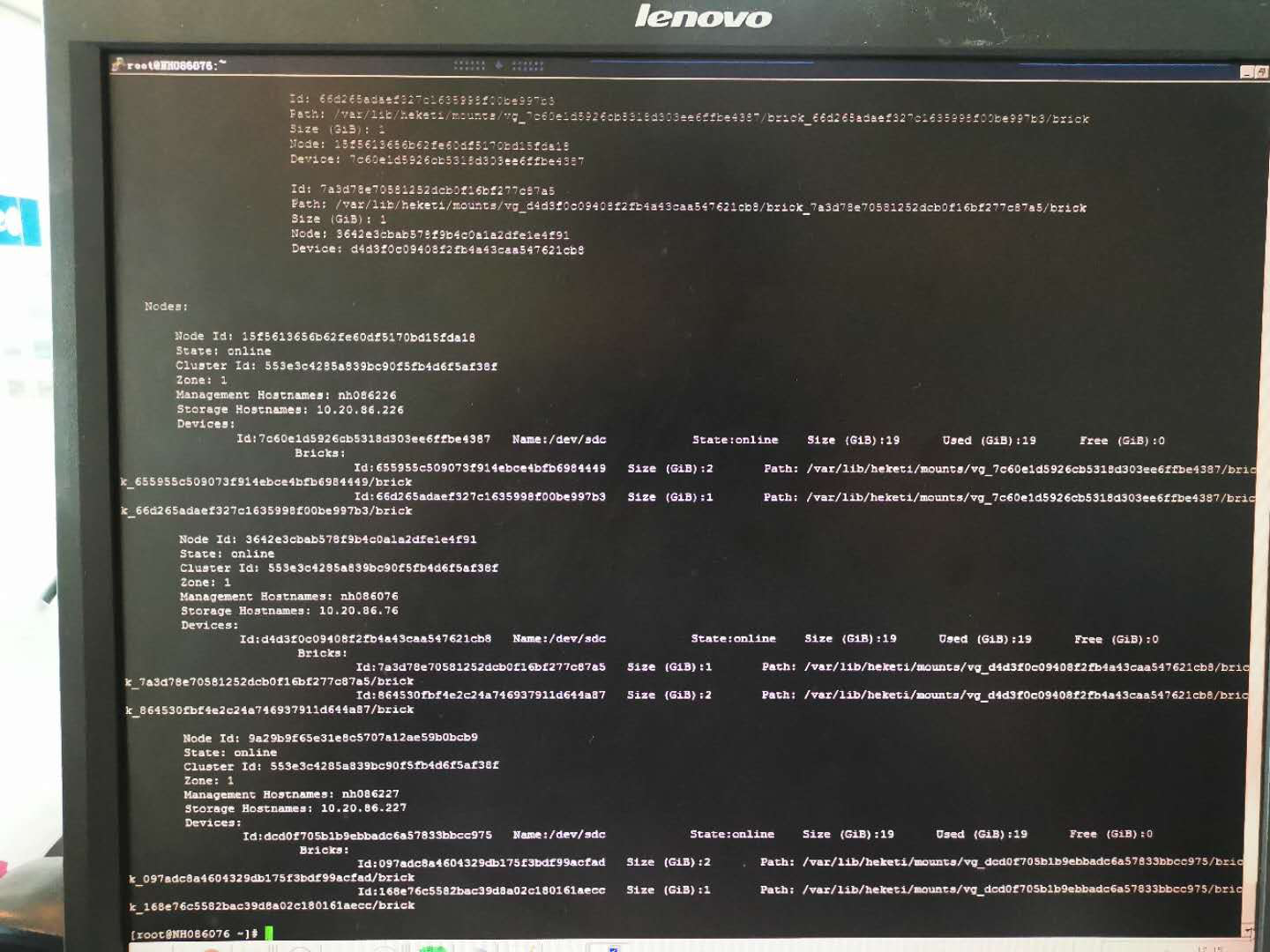
查看db中是否存在待处理请求导致数据不一致的。
1 | heketi-cli server operations info |
发现没有异常状态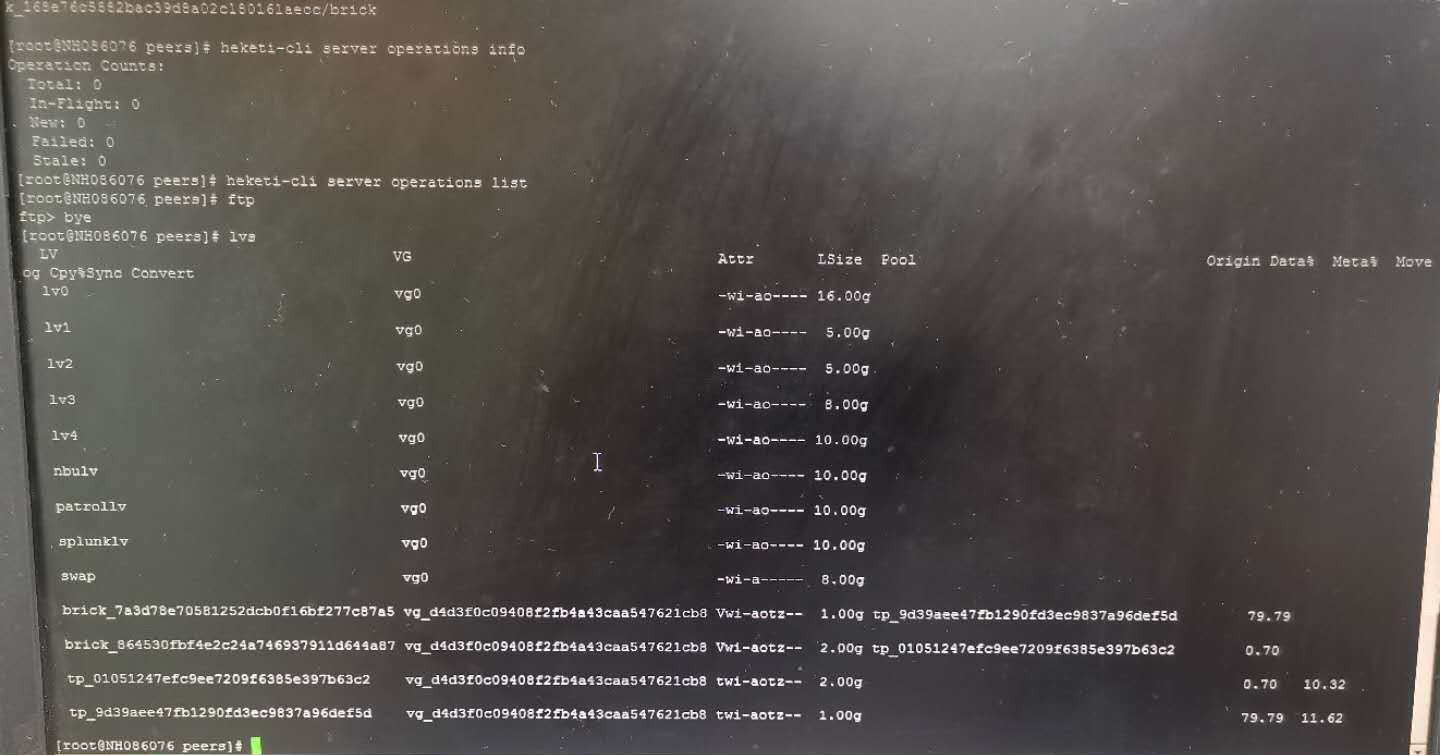
检查db中的状态
heketi-cli db check发现异常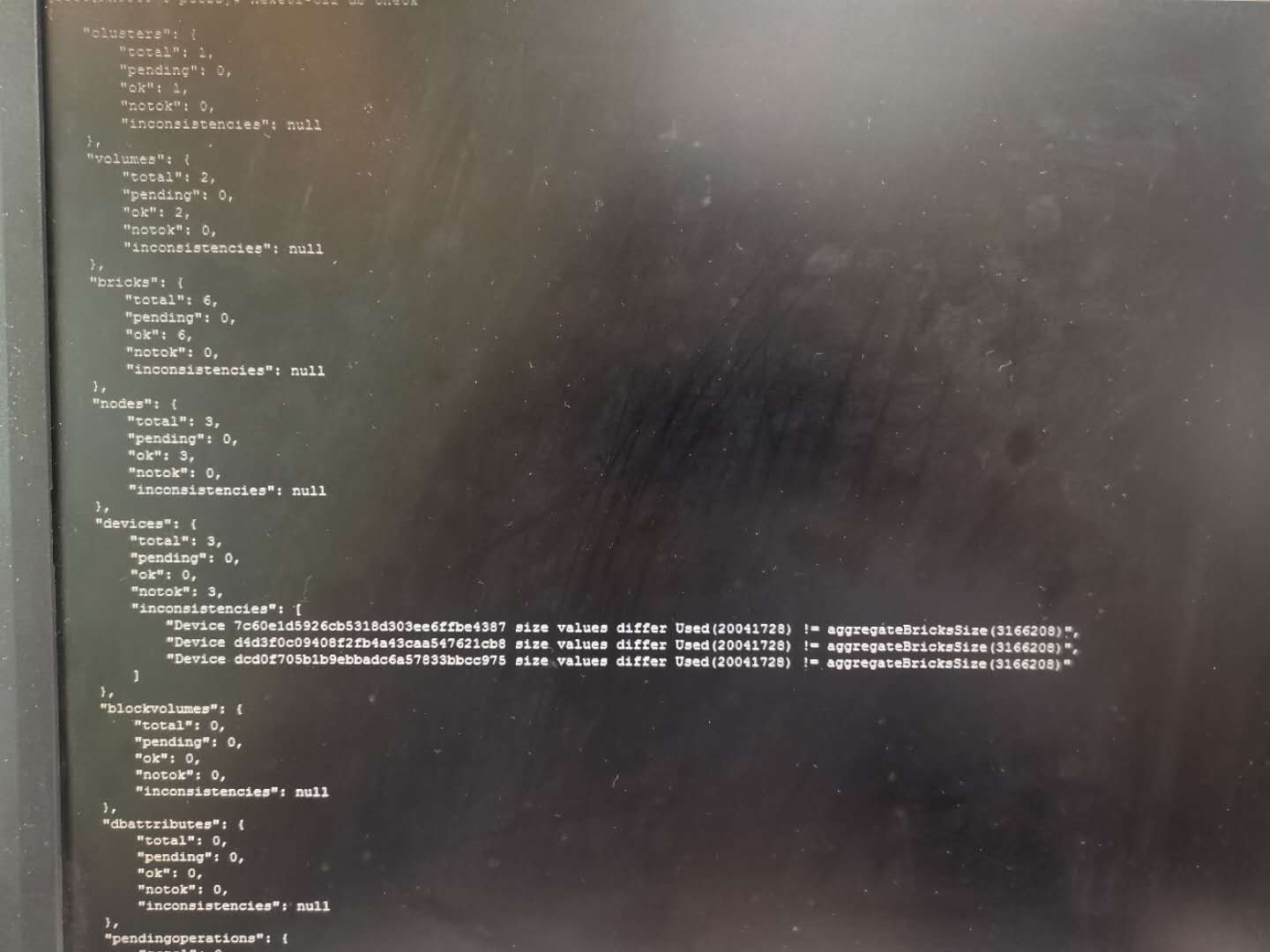
问题原因
heketi与实际的存储设备使用空间不匹配
解决策略
尝试使用设备同步命令测试:
1 | heketi-cli device resync $<device> |
heketi与gfs卷数量不一致
glusterfs 7.1 heketi v9.0.0 kubernetes 1.17.0
问题描述
通过heketi查看到的volume数量与gluster查看到的不一致
通过heketi查看到的volume卷:1个10G、1个2G(heketidb)、3个1G。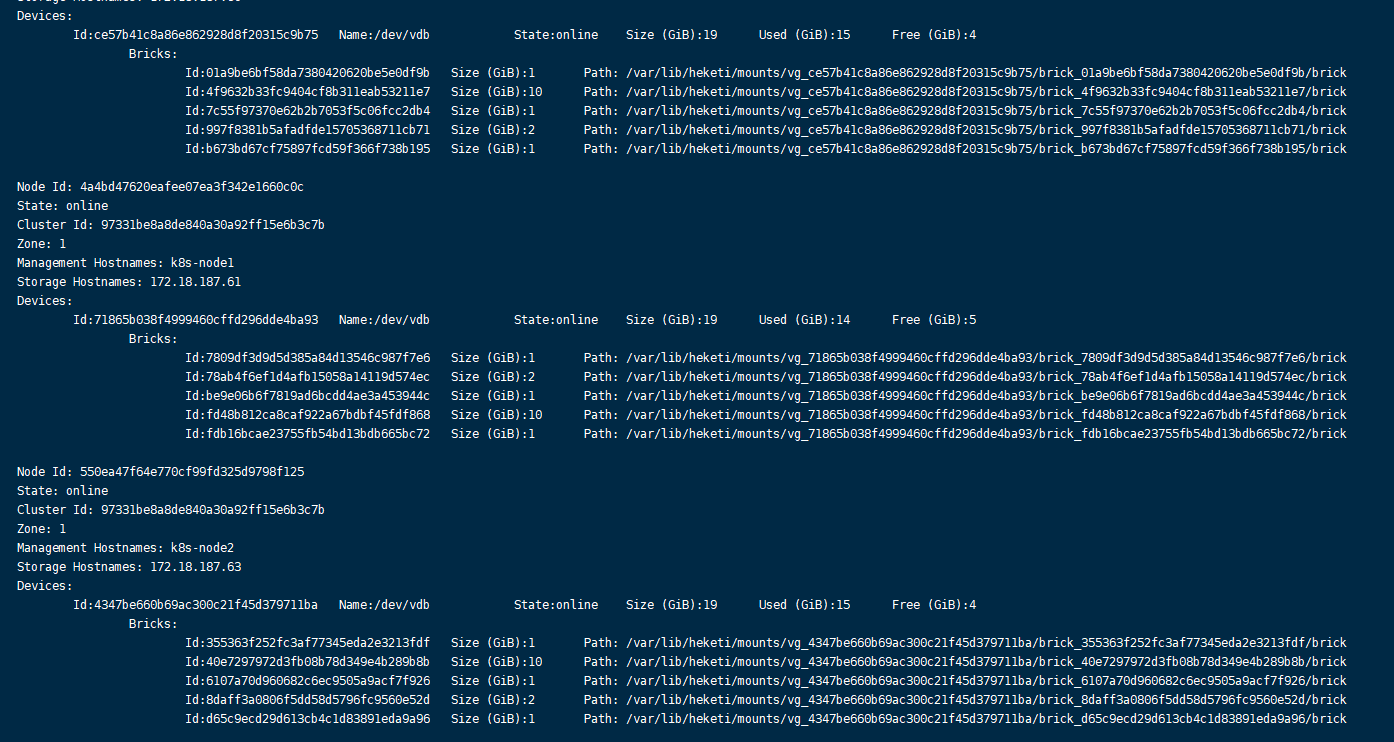

通过gluster查看volume卷,可以确认实际使用的卷为3个。1个10G、1个2G(heketidb)、2个1G。
解决策略
确认异常卷id信息

此时如果通过heketi-cli命令删除(heketi-cli volume delete VOLUME_ID)将会报设备繁忙:target is busy。
1 | Error: umount: /var/lib/heketi/mounts/vg_NAME/brick_XXXXXX: target is busy. |
确认gfs节点上的异常lv设备
查看该设备被那些进程或文件所占用。如下可以看到该brick被进程占用,所以删除时会报设备繁忙。
通过fuser -kuc NAME进行搜索并且杀死进程后,可通过heketi-cli命令正常删除异常volume卷。
